
This article has been machine-translated from Chinese. The translation may contain inaccuracies or awkward phrasing. If in doubt, please refer to the original Chinese version.
Source code repository: CompilePrincipleLearning/experiment_2 · yusixian/CompilePrincipleLearning (github.com)
I. Experiment Objective
- Master the basic principles of LL(1) parsing
- Master the construction method of LL(1) parse tables
- Master the construction method of LL(1) driver programs
II. Experiment Content and Requirements
Write a lexical analysis program that recognizes tokens.
Based on a given grammar, compile and debug an LL(1) parsing program to analyze any input symbol string. The purpose of this experiment is primarily to deepen understanding of the predictive analysis LL(1) parsing method.
Example: For the following grammar, use LL(1) parsing to analyze any input symbol string:
(1) E->TG
(2) G->+TG|-TG
(3) G->e
(4) T->FS
(5) S->*FS|/FS
(6) S->e
(7) F->(E)
(8) F->i
Output format as follows:
(1) LL(1) parsing program, developed by: Name, Student ID, Class
(2) Enter a symbol string ending with # (including +*()i#): i*(i+i)+(i*i)#
(3) Output process steps as follows:
| Step | Analysis Stack | Remaining Input | Production Used |
|---|---|---|---|
| 1 | E | i+i*i# | E->TG |
(4) The input symbol string is an illegal symbol string (or a legal symbol string)
Notes:
(1) In the “Production Used” column, if a derivation applies, write the production used; if matching a terminal, specify the matched terminal; if analysis encounters an error, write “Analysis Error”; if successfully completed, write “Analysis Successful”.
(2) The input symbol string is user-provided.
(3) The output process described above is only partial.
Note: 1. Expressions may use operators (+-*/), delimiters (parentheses), character i, and end symbol #;
-
If an erroneous expression is encountered, output error prompt information (the more detailed the better);
-
For advanced students, test expressions should be pre-stored in a text file, one expression per line, separated by semicolons. Expected output results should be written in another text file for comparison;
-
Other grammars may be used.
III. Experiment Process
1. Data Structures Used
Production type is defined as type, with origin as the left side (uppercase character) and the right side as the produced characters.
struct type { /*产生式类型定义 */
char origin; /*产生式左侧字符 大写字符 */
string array; /*产生式右边字符 */
int length; /*字符个数 */
type():origin('N'), array(""), length(0) {}
void init(char a, string b) {
origin = a;
array = b;
length = array.length();
}
};Initialization data structures are as follows:
e.init('E', "TG"), t.init('T', "FS");
g.init('G', "+TG"), g1.init('G', "^");
s.init('S', "*FS"), s1.init('S', "^");
f.init('F', "(E)"), f1.init('F', "i");2. Header File Declarations and Global Variable Definitions
As follows:
#include <iostream>
#include <string>
#include <fstream>
#include <vector>
#include <cstring>
using namespace std;
const string ExpFileName = "./exp.txt";
char analyeStack[20]; /*分析栈*/
char restStack[20]; /*剩余栈*/
const string v1 = "i+*()#"; /*终结符 */
const string v2 = "EGTSF"; /*非终结符 */
const string acceptStr = "i+*()#"; // 接受的字符串
int top, ridx, len; /*len为输入串长度 */
struct type { /*产生式类型定义 */
char origin; /*产生式左侧字符 大写字符 */
string array; /*产生式右边字符 */
int length; /*字符个数 */
type():origin('N'), array(""), length(0) {}
void init(char a, string b) {
origin = a;
array = b;
length = array.length();
}
};
type e, t, g, g1, s, s1, f, f1; /* 产生式结构体变量 */
type C[10][10]; /* 预测分析表 */4. Function Summary
(1) Function Summary Table
| Function Name | Brief Description |
|---|---|
readFile | File reading function, returns a dynamic string array split by lines |
init | Initialization function, initializes analysis stack and remaining stack |
print | Outputs current analysis stack and remaining stack |
isTerminator | Checks if character c is a terminal symbol |
analyze | Analyzes string s and outputs its analysis steps |
main | Main program entry, fills initial parse table and initializes productions, calls file reading function to begin analysis |
(2) Function Call Relationships
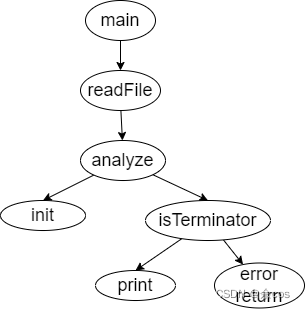
5. Experiment Results
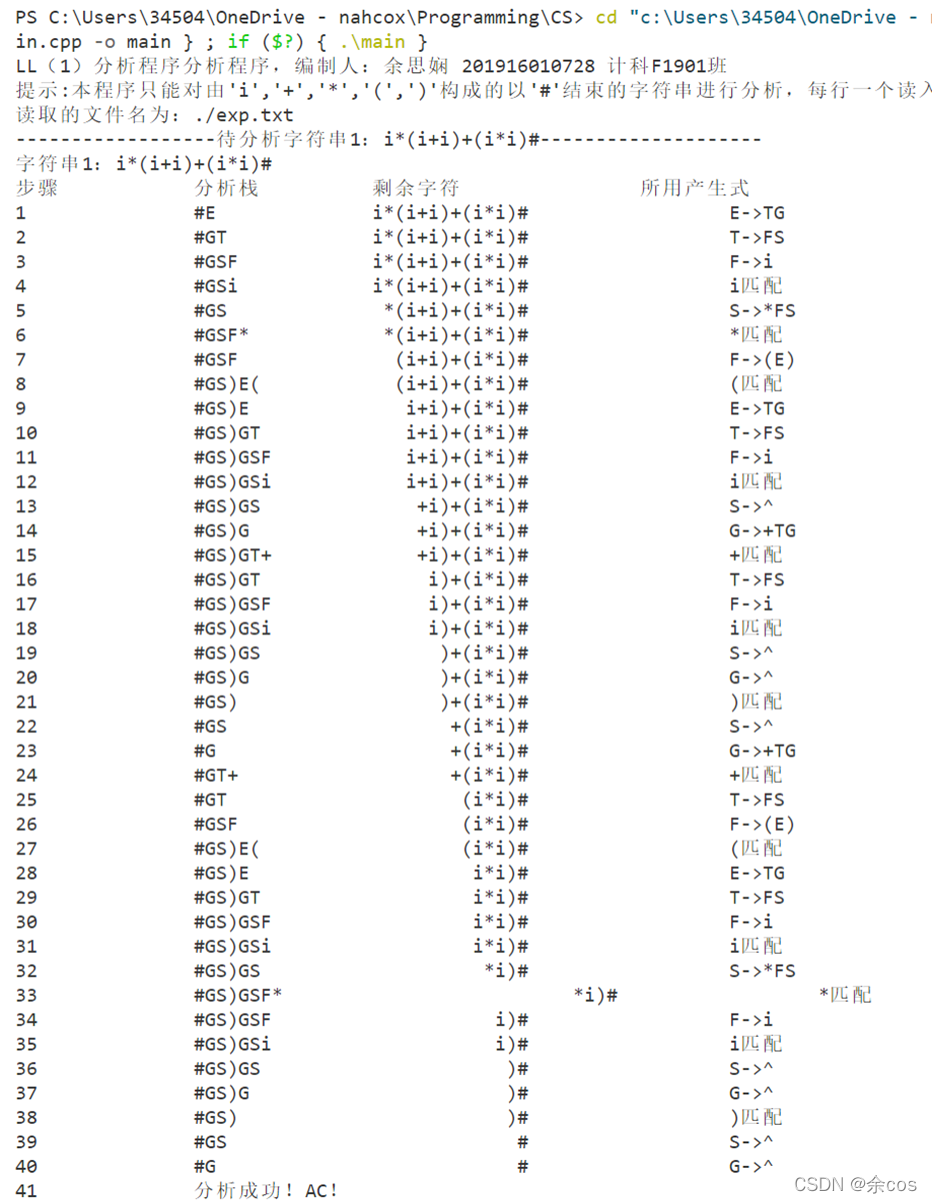
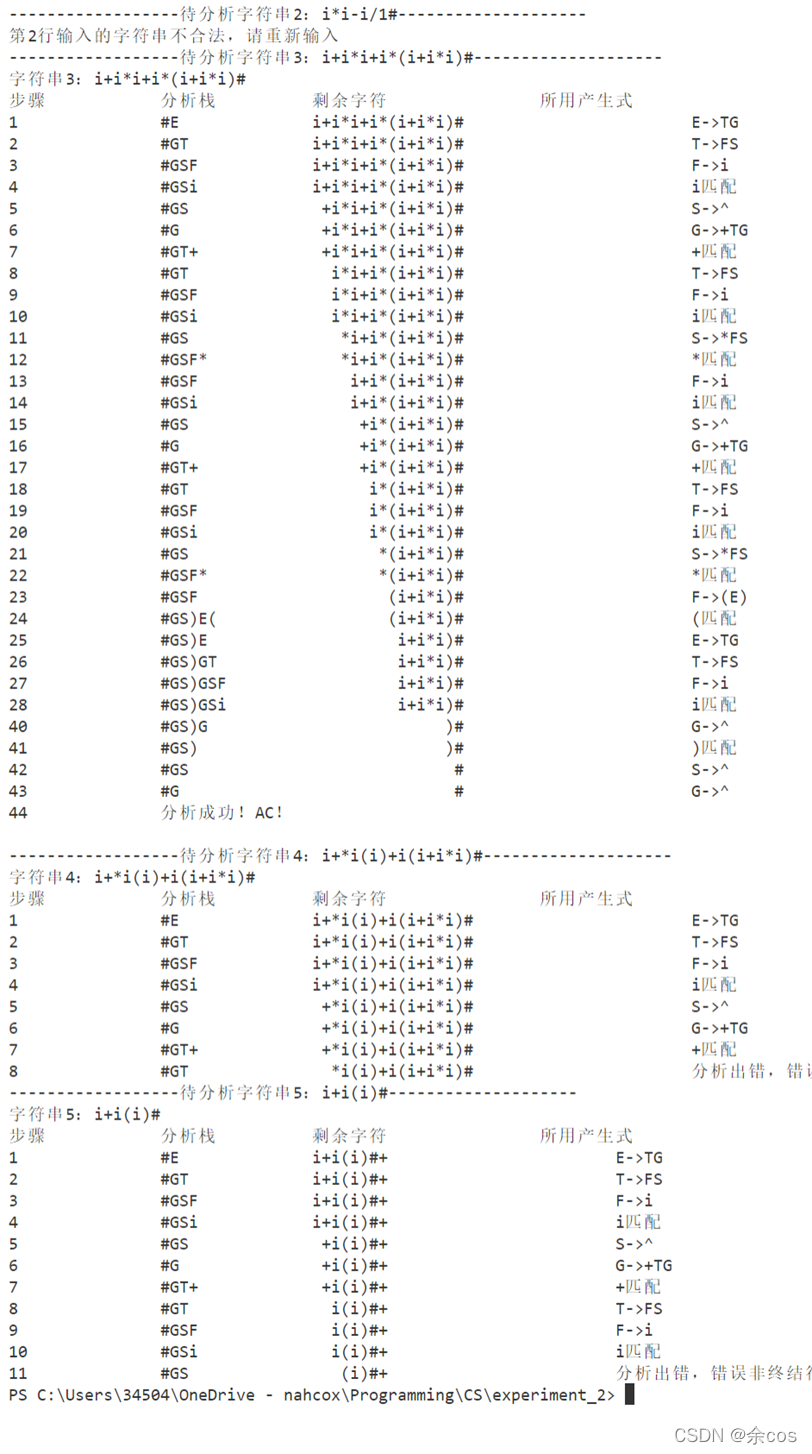
Input
File exp.txt
i*(i+i)+(i*i)#
i*i-i/1#
i+i*i+i*(i+i*i)#
i+*i(i)+i(i+i*i)#
i+i(i)#code.txtOutput
Complete Code
/*
* @Author: cos
* @Date: 2022-04-12 23:03:36
* @LastEditTime: 2022-04-13 01:32:58
* @LastEditors: cos
* @Description:
* @FilePath: \CS\experiment_2\main.cpp
*/
#include <iostream>
#include <string>
#include <fstream>
#include <vector>
#include <cstring>
using namespace std;
const string ExpFileName = "./exp.txt";
char analyeStack[20]; /*分析栈*/
char restStack[20]; /*剩余栈*/
const string v1 = "i+*()#"; /*终结符 */
const string v2 = "EGTSF"; /*非终结符 */
int top, ridx, len; /*len为输入串长度 */
struct type { /*产生式类型定义 */
char origin; /*产生式左侧字符 大写字符 */
string array; /*产生式右边字符 */
int length; /*字符个数 */
type():origin('N'), array(""), length(0) {}
void init(char a, string b) {
origin = a;
array = b;
length = array.length();
}
};
type e, t, g, g1, s, s1, f, f1; /* 产生式结构体变量 */
type C[10][10]; /* 预测分析表 */
void print() {/*输出分析栈和剩余栈 */
for(int i = 0; i <= top + 1; ++i) /*输出分析栈 */
cout << analyeStack[i];
cout << "\t\t";
for(int i = 0; i < ridx; ++i) /*输出对齐符*/
cout << ' ';
for(int i = ridx; i <= len; ++i) /*输出剩余串*/
cout << restStack[i];
cout << "\t\t\t";
}
// 读文件
vector<string> readFile(string fileName) {
vector<string> res;
try {
ifstream fin;
fin.open(fileName);
string temp;
while (getline(fin, temp))
res.push_back(temp);
return res;
} catch(const exception& e) {
cerr << e.what() << '\n';
return res;
}
}
bool isTerminator(char c) { // 判断是否是终结符
return v1.find(c) != string::npos;
}
void init(string exp) {
top = ridx = 0;
len = exp.length(); /*分析串长度*/
for(int i = 0; i < len; ++i)
restStack[i] = exp[i];
}
void analyze(string exp) { // 分析一个文法
init(exp);
int k = 0;
analyeStack[top] = '#';
analyeStack[++top] = 'E'; /*'#','E'进栈*/
cout << "步骤\t\t分析栈 \t\t剩余字符 \t\t所用产生式 " << endl;
while(true) {
char ch = restStack[ridx];
char x = analyeStack[top--]; /*x为当前栈顶字符*/
cout << ++k << "\t\t";
if(x == '#') {
cout << "分析成功!AC!\n" << endl; /*接受 */
return;
}
if(isTerminator(x)) {
if (x == ch) { // 匹配上了
print();
cout << ch << "匹配" << endl;
ch = restStack[++ridx]; /*下一个输入字符*/
} else { /*出错处理*/
print();
cout << "分析出错,错误终结符为" << ch << endl; /*输出出错终结符*/
return;
}
} else { /*非终结符处理*/
int m, n; // 非终结符下标, 终结符下标
v2.find(x) != string::npos ? m = v2.find(x) : -1; // m为-1则说明找不到该非终结符,出错
v1.find(ch) != string::npos ? n = v1.find(ch) : -1; // n为-1则说明找不到该终结符,出错
if(m == -1 || n == -1) { /*出错处理*/
print();
cout << "分析出错,错误非终结符为" << x << endl; /*输出出错非终结符*/
return;
}
type nowType = C[m][n];/*用来接受C[m][n]*/
if(nowType.origin != 'N') {/*判断是否为空*/
print();
cout << nowType.origin << "->" << nowType.array << endl; /*输出产生式*/
for (int j = (nowType.length - 1); j >= 0; --j) /*产生式逆序入栈*/
analyeStack[++top] = nowType.array[j];
if (analyeStack[top] == '^') /*为空则不进栈*/
top--;
} else { /*出错处理*/
print();
cout << "分析出错,错误非终结符为" << x << endl; /*输出出错非终结符*/
return;
}
}
}
}
int main() {
e.init('E', "TG"), t.init('T', "FS");
g.init('G', "+TG"), g1.init('G', "^");
s.init('S', "*FS"), s1.init('S', "^");
f.init('F', "(E)"), f1.init('F', "i"); /* 结构体变量 */
/*填充分析表*/
C[0][0] = C[0][3] = e;
C[1][1] = g;
C[1][4] = C[1][5] = g1;
C[2][0] = C[2][3] = t;
C[3][2] = s;
C[3][4] = C[3][5] = C[3][1] = s1;
C[4][0] = f1; C[4][3] = f;
cout << "LL(1)分析程序分析程序,编制人:xxx xxx 计科xxxx班" << endl;
cout << "提示:本程序只能对由'i','+','*','(',')'构成的以'#'结束的字符串进行分析,每行一个读入的字符串" << endl;
cout << "读取的文件名为:" << ExpFileName << endl;
vector<string> exps = readFile(ExpFileName);
int len = exps.size();
for(int i = 0; i < len; i++) {
string exp = exps[i];
cout << "------------------待分析字符串" << i+1 << ":"<< exp << "--------------------" << endl;
bool flag = true;
for(int j = 0; j < exp.length(); j++) {
if(!isTerminator(exp[j])) {
cout << "第"<< i+1 << "行输入的字符串不合法,请重新输入" << endl;
flag = false;
break;
}
}
if(flag) {
cout << "字符串" << i+1 << ":" << exp << endl;
analyze(exp);
}
}
return 0;
}
喜欢的话,留下你的评论吧~